RESOUND: Speech Reconstruction from Silent Videos
via Acoustic-Semantic Decomposed Modeling
Interspeech 2025
Abstract
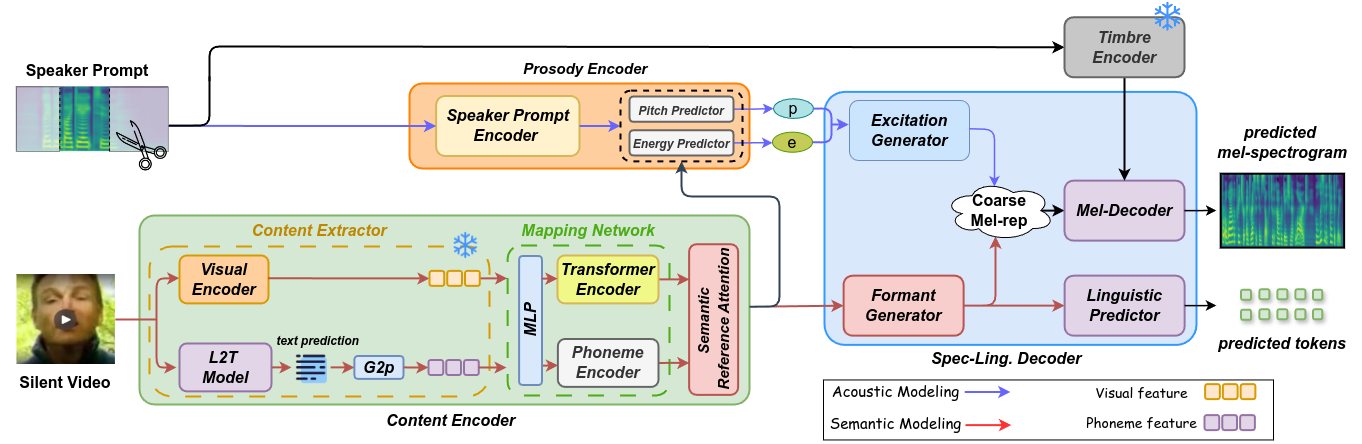
Lip-to-Speech (L2S) synthesis task, which reconstructs speech from visual cues, faces challenges in accuracy and naturalness due to limited supervision in capturing linguistic content, accents, and prosody. In this paper, we propose RESOUND, a novel L2S framework that generates intelligible and expressive speech from silent talking face videos. Leveraging source-filter theory, RESOUND splits into two pathways: an acoustic path for predicting prosody and a semantic path for extracting linguistic features. This separation simplifies learning, allowing independent optimization of each representation. Additionally, we enhance performance by integrating speech units, a proven unsupervised speech representation technique, into waveform generation alongside mel-spectrograms. This structure allows RESOUND to synthesize high-accuracy prosodic speech while preserving content and speaker identity. Experiments show that RESOUND outperforms prior state-of-the-art L2S methods across multiple metrics.
Model Architecture